Category: Data
-
Alucinación – el termino para cuando los modelos de inteligencia artificial se equivocan
Aunque es impresionante el hecho de que un chatbot responde a un input, académicos, científicos y expertos en la aplicación de la inteligencia artificial no han definido su postura con respeto al IA en términos psicológicos. La ciencia cognitiva bien fue la inspiración para las llamadas ‘redes neuronales’ que definen la arquitectura de algunos de […]
-

Explicit Content Related To Mexicans – Please Review
For cultural news, please see here: Chicano Culture. In this page, we review possibly objectionable content related to Mexicans. We have stored these tweets in a database. Many people make statements on Twitter ‘with a pinch of salt’. However, therein lies a powerful question: who gets to define what is simply a cheeky reference and […]
-

Chicano Chatter On Twitter
Check out the latest chatter from people using the word ‘Chicano’ on twitter. In an effort to highlight more content, we developed a few database queries to routinely retrieve uncontroversial tweets. Some of these contain frivolous references or insightful comments. Unfortunately, in many social media platforms, some of the least informed content often gets more […]
-
US Employee Pensions Finance PEGASUS Software; University of California, CALPERS Among Group
This article is reshared with permission from La Cartita. Originally published in that platform 12/16/2017. La Cartita — (6/30/2017) — PEGASUS is the worlds most advanced spyware, a special type of software designed to spy on cellular phones and computers without the user’s permission. The software is most often used to target a victim’s phone […]
-
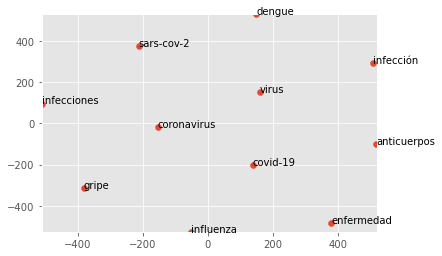
Word2Vec Mexican Spanish Model: Lyrics, News Documents
A Corpus That Contains Colloquial Lyrics & News Documents For Mexican Spanish This experimental dataset was developed by 4 Social Science specialists and one industry expert, myself, with different samples from Mexico specific news texts and normalized song lyrics. The intent is to understand how small, phrase level constituents will interact with larger, editorialized style […]
-
Semantic Similarity & Visualizing Word Vectors
Introduction: Two Views On Semantic Similarity In Linguistics and Philosophy of Language, there are various methods and views on how to best describe and justify semantic similarity. This tutorial will be taken as a chance to lightly touch upon very basic ideas in Linguistics. We will introduce in a very broad sense the original concept […]
-
Leveraging NVIDIA Downloads
An issue during the installation of TensorFlow in the Anaconda Python environment is an error message citing the lack of a DLL file. Logically, you will also receive the same error for invoking any Spacy language models, which need TensorFlow installed properly. Thus, running the code below will invoke an error message without the proper […]
Recent Posts
- The Crucial Role of Linear Algebra in Natural Language Processing

- Artificial Intelligence Could Help Engage Homeless Populations, But Organizations Must Be Ready

- Alucinación – el termino para cuando los modelos de inteligencia artificial se equivocan
- Barbie debuta en Mexico, Colombia, Uruguay y Estados Unidos este viernes
- Air Quality in Chicago Declines to “Very Unhealthy” Levels as Alert Issued
Tags
Alejandra del Moral Apple Artificial Intelligence Bill Gates Boxing business California Canada ChatGPT China Colombia crime culture Delfina Gomez Dollar Donald trump drugs drug traffic Economy EE.UU. Elon Musk environment fentanyl Florida france Gustavo Petro Human rights Italy Joe Biden Latin music LGBTQ Mexico New York Peso Pluma Policy Ron DeSantis RUSSIA Security Shooting technology Ukraine Ukraine crisis united states Violence WAR