Category: Python
-

WebScraping As Sourcing Technique For NLP
Introduction In this post, we provide a series of web scraping examples and reference for people looking to bootstrap text for a language model. The advantage is that a greater number of spoken speech domains could be covered. Newer vocabulary or possibly very common slang is picked up through this method since most corporate language […]
-
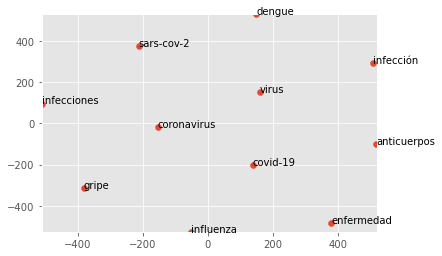
Word2Vec Mexican Spanish Model: Lyrics, News Documents
A Corpus That Contains Colloquial Lyrics & News Documents For Mexican Spanish This experimental dataset was developed by 4 Social Science specialists and one industry expert, myself, with different samples from Mexico specific news texts and normalized song lyrics. The intent is to understand how small, phrase level constituents will interact with larger, editorialized style […]
-
Semantic Similarity & Visualizing Word Vectors
Introduction: Two Views On Semantic Similarity In Linguistics and Philosophy of Language, there are various methods and views on how to best describe and justify semantic similarity. This tutorial will be taken as a chance to lightly touch upon very basic ideas in Linguistics. We will introduce in a very broad sense the original concept […]
-
Leveraging NVIDIA Downloads
An issue during the installation of TensorFlow in the Anaconda Python environment is an error message citing the lack of a DLL file. Logically, you will also receive the same error for invoking any Spacy language models, which need TensorFlow installed properly. Thus, running the code below will invoke an error message without the proper […]
-
Frequency Counts For Named Entities Using Spacy/Python Over MX Spanish News Text
On this post, we review some straightforward code written in python that allows a user to process text and retrieve named entities alongside their numerical counts. The main dependencies are Spacy, a small compact version of their Spanish language model built for Named Entity Recognition and the tabular data processing library, Matplotlib, if you’re looking […]
-
Using Spacy in Python To Extract Named Entities in Spanish
The Spacy Small Language model has some difficulty with contemporary news text that are not either Eurocentric or US based. Likely, this lack of accuracy with contemporary figures owes in part to a less thorough scrape of Wikipedia and relative changes that have taken place in Mexico, Bolivia and other countries with highly variant dialects […]
-

Introducción a Python
Python es un lenguaje de programación bastante flexible y veloz cuando seconsidera que es un lenguaje de alto nivel. En este breve resumen del idioma se presenta un ejercicio que abre un archivo. Esta tarea es casi rutinaria en todo trabajo complejo. Ahora, si buscas un ejercicio más avanzado o uno que simplemente abarca un tema […]
Recent Posts
- The Crucial Role of Linear Algebra in Natural Language Processing

- Artificial Intelligence Could Help Engage Homeless Populations, But Organizations Must Be Ready

- Alucinación – el termino para cuando los modelos de inteligencia artificial se equivocan
- Barbie debuta en Mexico, Colombia, Uruguay y Estados Unidos este viernes
- Air Quality in Chicago Declines to “Very Unhealthy” Levels as Alert Issued
Tags
Alejandra del Moral Apple Artificial Intelligence Bill Gates Boxing business California Canada ChatGPT China Colombia crime culture Delfina Gomez Dollar Donald trump drugs drug traffic Economy EE.UU. Elon Musk environment fentanyl Florida france Gustavo Petro Human rights Italy Joe Biden Latin music LGBTQ Mexico New York Peso Pluma Policy Ron DeSantis RUSSIA Security Shooting technology Ukraine Ukraine crisis united states Violence WAR