Voice Assistants Methods Can Guide LLM Deployment: Redefining Success
LLM’s ubiquitous use has changed the game on all surface spaces that involve computing. I speak in the most general sense to underscore how broad the scope of its current and future impact will be.
Even partial fulfillment of the various Gen AI promises gives a clear signal for all information technology practitioners to tighten up their expertise in techniques specific to language models (LM). It may come as a surprise, then, that the NLP and AI evaluation methods that have been present since the 1990s continue to evaluate the performance of language models. These tried and true evaluation approaches focus on quantitative precision metrics that measure a model’s ability to predict the correct label class of a particular new input.
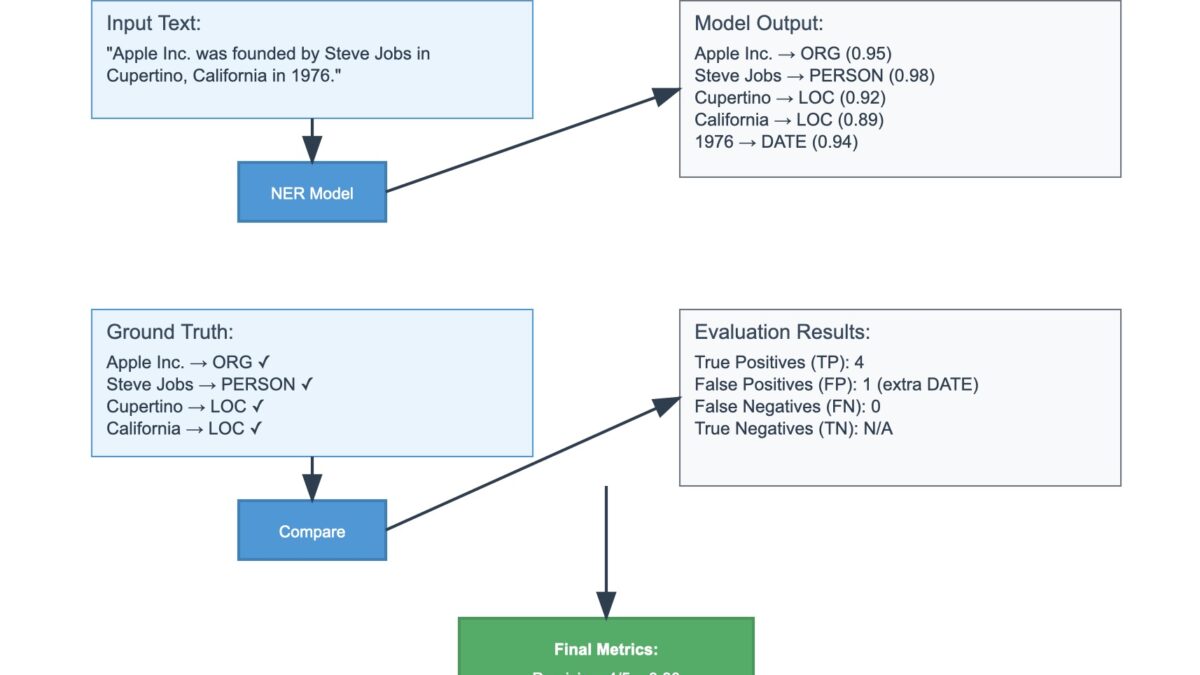
These traditional metrics were designed for more narrowly defined tasks: sentiment classification, named entity recognition, part-of-speech tagging, and similar problems where there’s typically a single correct answer. They work well when you can clearly define ground truth and measure how often a model gets the “right” classification.
However, as large language models (LLMs) continue to power increasingly complex and human-facing applications—chatbots, tutors, copilots, agents—the question of what counts as success becomes both urgent and difficult. The interpretive lense with which we eval these models needs to center the end user.
Foundational models have become victims of their initial success. In being able to provide a reasonable response to a myriad of user inputs, the models are facilitating the range of use, but also the range for possible failure. Thus, an interpretive lense for tasks and refinements seems better than too fine grained an approach for in the traditional sense.
Nuanced Approaches From NLP
Traditional NLP evaluation metrics like BLEU, ROUGE, and exact match scores offer a limited view into language model performance. While useful for benchmarking and development, they fall short when evaluating real-world performance, especially in open-ended, goal-oriented tasks, like a user action on an application. For that end, we need to adopt a more human-centered approach.
Small increments in performance for any given foundational model probably won’t have consequences for end user input, at the very least, they probably aren’t even being measured which is really my point.
One of the most promising concepts comes from an unexpected place: voice assistants. In that domain, which is fairly well established relative to the LLM conversational (text) applications, teams have long used a metric(s) centered around Success Rate or Task Completion to measure how well a system actually fulfills user intent. Whether it’s capturing word error rate or its inverse
What Is Task Success Rate (TS) Over Shared Questions?
A human Task Success/Task Completion Rate is a subjective but structured evaluation made by trained human graders. In many contexts, the data they produce is called “Gold Data” or “Gold Standard Data”. The core questions around qualitative control they answered are roughly:
- Did the user accomplish what they wanted to accomplish?
- Was the system’s output appropriate, helpful, and complete?
Remember, the tasks are specific and center on some type of demarcation or specialization for a domain, like biology or any other specialized body of knowledge and facts, but are usually not out of reach for human evaluators or annotators with a specific background.
There is already a research effort led by the usual players from the usual places to provide some type higher burden standardization for foundational models. For instance, ‘A Benchmark for General AI Assistants’ offers hints at the approach to take. The FAIR team attempts to standardize a set of questions that are already difficult for foundational models. Specifically, they invoke GPT-4 infused application question errors against human annotators. In these questions, the former scored a mere 14 percent, but humans boasted 92 percent accuracy.
There is some bias in this approach, perhaps, not enough to question the enterprise but enough to be noted. The research group is from Meta and scrutinizing their biggest and most formidable rival in OpenAI.
Nevertheless, the ability to establish a multimodal leaderboard seems promising. What could throttle the enterprise is a set of base questions, like their 400+ questions, would have to presume access to the same data, and behind a closed model, like OpenAI, there’s little way to deconstruct why or how a response is wrong. Perhaps, foundational models would first need to agree on being able to mutually assume the same open source data. We already know that there’s a few baseline assumptions with regards to data.
The point is model behavior now goes beyond correctness and into satisfaction, efficiency, and outcome. For example, an LLM that returns a grammatically correct yet non-actionable response may score high on automatic metrics—but fail Task Success. Due to the nature of human perception, in many voice assistant programs, hTSR is treated as the ground truth, forming the foundation on which automated metrics are calibrated and improved.
The Broader ‘Task Success Rate’ (TSR) Helps Scale Faster
While human evaluation is critical, it is slow, expensive, and unscalable. When you have a series of if-then statements that can, perhaps, by placed into a script, this does tend to lend itself to faster quality control checks. This has led to the development of QC processes that use logs, intent mapping, and system telemetry to determine whether a task was completed correctly in multiple environment.
But Automated TSR has limitations. It often overestimates success by treating certain actions—like “calling John” or “sending a message”—as always successful, without checking if they were wanted or understood correctly. It may also miss important failure signals unless those are explicitly encoded in the logic.
To address these gaps, the speech recognition community has begun to think of Auto TSR as a funnel, where traffic marked as “successful” must pass through increasingly precise filters to remove false positives.
Several signals are proving especially useful in voice and LLM contexts:
1. Redundancy
The overall concept of repeated inputs that is left unexploited is making its way into LLM powered interactions. These are being explored in somewhat connected ways in (Klubička & Kelleher, 2024) and GRUEN metric’s “non-redundancy” component that detects repeated text in AI-generated content. The basic questions are: “do users repeat the same requests?”.
This could indicate either high engagement (good) or dissatisfaction (bad). In LLM chats, repeating “Can you explain again?” or “Let me clarify” may hint at unresolved needs. This idea of redundancy takes inspiration from an era in speech recognition where researchers had to ‘guesstimate’ the signal to noise ratio and calculate white noise.
2. Reformulation
Are prompts being slightly reworded? This behavior often signals that the user is trying to guide or correct the model. For instance:
“Turn it off” → “Turn off the screen” → “Shut down the display.”
In a chat, this may appear as:
- “What is LTV?” → “Explain LTV like I’m 5” → “Give an example of LTV in SaaS”
3. Frustration
Emotive language like “that’s not what I asked for” or “ugh, never mind” can be strong indicators of failed interaction. Future models may also use prosodic and audio signals to detect this in speech contexts.
Ultimately, we are seeing new metrics and qualitative measures over which to iterate and expand our evaluation of LLM’s. Fun times to be a linguist!