Word2Vec Mexican Spanish Model: Lyrics, News Documents
A Corpus That Contains Colloquial Lyrics & News Documents For Mexican Spanish
This experimental dataset was developed by 4 Social Science specialists and one industry expert, myself, with different samples from Mexico specific news texts and normalized song lyrics. The intent is to understand how small, phrase level constituents will interact with larger, editorialized style text. There appears to be no ill-effect with the combination of varied texts.
We are working on the assumption that a single song is a document. A single news article is a document too.
In this post, we provide a Mexican Spanish Word2Vec model compatible with the Gensim python library. The word2vec model is derived from a corpus created by 4 research analysts and myself. This dataset was tagged at the document level for the topic of ‘Mexico’ news. The language is Mexican Spanish with an emphasis on alternative news outlets.
One way to use this WVModel is shown here: scatterplot repo.
Lemmatization Issues
We chose to not lemmatize this corpus prior to including in the word vector model. The reason is two-fold: diminished performance and prohibitive runtime length for the lemmatizer. It takes close to 8 hours for a Spacy lemmatizer to run through the entire set of sentences and phrases. Instead, we made sure normalization was sufficiently accurate and factored out major stopwords.
Training Example
Below we show some basic examples as to how we would train based on the data text. The text is passed along to the Word2Vec module. The relevant parameters are set, but the user/reader can change as they see fit. Ultimately, this saved W2V model will be saved locally.
In this case, the named W2Vec model “Mex_Corona_.w2v” is a name that will be referenced down below in top_5.py.
from gensim.models import Word2Vec, KeyedVectors
important_text = normalize_corpus('C:/<<ZYZ>>/NER_news-main/corpora/todomexico.txt')
#Build the model, by selecting the parameters.
our_model = Word2Vec(important_text, vector_size=100, window=5, min_count=2, workers=20)
#Save the model
our_model.save("Mex_Corona_.w2v")
#Inspect the model by looking for the most similar words for a test word.
#print(our_model.wv.most_similar('mujeres', topn=5))
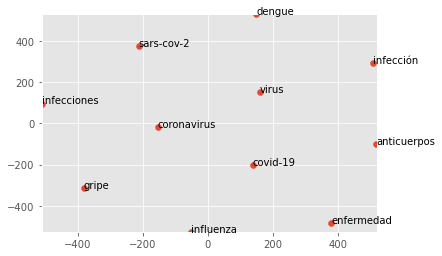
scatter_vector(our_model, 'Pfizer', 100, 21) Corpus Details
Specifically, from March 2020 to July 2021, a group of Mexico City based research analysts determined which documents were relevant to this Mexico news category. These analysts selected thousands of documents, with about 1200 of these documents at an average length of 500 words making its way to our Gensim language model. Additionally, the corpus contained here is made out of lyrics with Chicano slang and colloquial Mexican speech.
We scrapped the webpages of over 300 Mexican ranchero and norteño artists on ‘https://letras.com‘. These artists ranged from a few dozen composers in the 1960’s to contemporary groups who code-switch due to California or US Southwest ties. The documents tagged as news relevant to the Mexico topic were combined with these lyrics with around 20 of the most common stopword removed. This greatly reduced the size of the original corpus while also increasing the accuracy of the word2vec similarity analysis.
In addition to the stop word removal, we also conducted light normalization. This was restricted to finding colloquial transcriptions and converting these to orthographically correct versions on song lyrics.
Normalizing Spanish News Data
Large corporations develop language models under guidance of product managers whose life experiences do not reflect that of users. In our view, there is a chasm between the consumer and engineer that underscores the need to embrace alternative datasets. Therefore, in this language model, we aimed for greater inclusion. The phrases are from a genre that encodes a rich oral history with speech commonly used amongst Mexicans in colloquial settings.
Song Lyrics For Colloquial Speech
This dataset contains lyrics from over 300 groups. The phrase length lyrics have been normalized to obey standard orthographic conventions. It also contains over 1000 documents labeled as relevant to Mexico news.

Github Lyrics Gensim Model
We have made the lyrics and news language model available. The model is contained here alongside some basic normalization methods on a module.
Colloquial Words
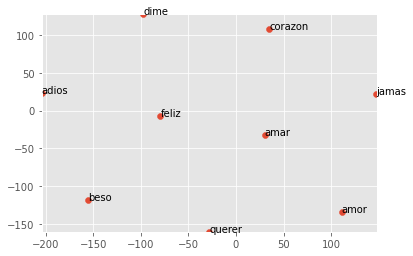
The similarity scores for a word like ‘amor’ (love) is shown below. In our colloquial/lyrics language model, we can see how ‘corazon’ is the closest to ‘amor’.
print(our_model.wv.most_similar('amor', topn=1))
[('corazon', 0.8519232869148254)]Let’s try to filter through the most relevant 8 results for ‘amor’:
scatter_vector('mx_lemm_ner-unnorm_1029_after_.w2v', 'amor', 100, 8)
Out[18]:
[('corazon', 0.8385680913925171),
('querer', 0.7986088991165161),
('jamas', 0.7974023222923279),
('dime', 0.788547158241272),
('amar', 0.7882217764854431),
('beso', 0.7817134857177734),
('adios', 0.7802879214286804),
('feliz', 0.7777709364891052)]For any and all inquiries, please send me a linkedin message here: Ricardo Lezama. The word2vec language model file is right here: Spanish-News-Colloquial.
Here is the scatterplot for ‘amor’:
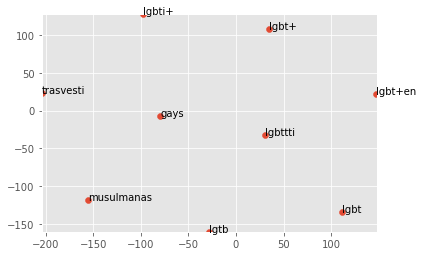
Diversity Inclusion Aspect – Keyterms
Visualizing the data is fairly simple. The scatterplot method allows us to show which terms surface in similar contexts.
Below, I provide an example of how to call the Word2Vec model. These Word2Vec documents are friendly to the Word2Vec modules.
from gensim.models import Word2Vec, KeyedVectors
coronavirus_mexico = "mx_lemm_ner-unnorm_1029_after_.w2v"
coronavirus = "coronavirus-norm_1028.w2v"
wv_from_text = Word2Vec.load(coronavirus)
#Inspect the model by looking for the most similar words for a test word.
print(wv_from_text.wv.most_similar('dosis', topn=5))
#Let us see what the 10-dimensional vector for 'computer' looks like.