Semantic Similarity & Visualizing Word Vectors
Introduction: Two Views On Semantic Similarity
In Linguistics and Philosophy of Language, there are various methods and views on how to best describe and justify semantic similarity. This tutorial will be taken as a chance to lightly touch upon very basic ideas in Linguistics. We will introduce in a very broad sense the original concept of semantic similarity as it pertains to natural language.
Furthermore, we will see how the linguistics view is drastically different from the state of the art Machine Learning techniques. I offer no judgments on why this is so. It’s just an opportunity to compare and contrast passively. Keeping both viewpoints in mind during an analysis is helpful. Ultimately, it maximizes our ability to understand valid Machine Learning output.
The Semantic Decomposition View
There is a compositional view that in its earliest 19th century incarnation is attributable to Gottleb Frege, in which the meaning of terms can be decomposed into simpler components such that the additive process of combining them yields a distinct meaning. Thus, two complex meanings may be similar to one another if they are composed of the same elements.
For example, the meaning of ‘king’ could be construed as an array of features, like the property of being human, royalty and male. Under this reasoning, the same features would carry over to describe ‘queen’, but the decomposition of the word would replace male with female. Thus, in the descriptive and compositional approach mentioned, categorical descriptions are assigned to words whereby decomposing a word reveals binary features for ‘human’, ‘royalty’ and ‘male’. Breaking down concepts represented by words into simpler meanings is what is meant with ‘feature decomposition’ in a semantic and linguistic context.
The Shallow Similarity View
Alternatively, Machine Learning approaches to semantic similarity involves a contextual approach towards the description of a word. In Machine Learning approaches, there is an assignment of shared indices between words. The word ‘king’ and ‘queen’ will appear in more contexts that are similar to one another than other words. In contrast, the words ‘dog’ or ‘cat’, which implies that they share more in common. Intuitively, we understand that these words have more in common due to their usage in very similar contexts. The similarity is represented as a vector in a graph. Each word can have closely adjacent vectors reflecting their similar or shared contexts.
Where both approaches eventually converge is in the ability for the output of a semantic theory or vector driven description of words matches with language users intuitions. In this tutorial and series of examples, we will observe how the Word2Vec module does fairly well with new, recent concepts that only recently appeared in mass texts. Furthermore, these texts are in Mexican Spanish, which implies that the normalization steps are unique to these pieces of unstructured data.
Working With Mexican Spanish In Word2Vec
In this series of python modules, I created a vector model from a Mexican Spanish news corpus. Each module has a purpose: normalization.py cleans text so that it can be interpretable for Word2Vec. Normalization also produces the output lists necessary to pass along to Gensim. Scatterplot.py visualizes the vectors.from the model. This corpus was developed as described below.
This dataset of 4000 documents is verified as being relevant to several topics. For this tutorial, there are three relevant topics: {Mexico, Coronavirus, and Politics}. Querying the model for words in this pragmatic domain is what is most sensible. This content exists in the LaCartita Db and is annotated by hand. The annotators are a group of Mexican graduates from UNAM and IPN universities. A uniform consensus amongst the news taggers was required for its introduction into the set of documents. There were 3 women and 1 man within the group of analysts, with all of them having prior experience gathering data in this domain.
While the 4000 Mexican Spanish news documents analyzed are unavailable on github, a smaller set is provided on that platform for educational purposes. Under all conditions, the data was tokenized and normalized with a set of Spanish centric regular expressions.
Please feel free to reach out to that group in research@lacartita.com for more information on this hand-tagged dataset.
Normalization in Spanish
There are three components to this script: normalizing, training a model and visualizing the data points within the model. This is why we have SkLearn and Matplotlib for visualization, gensim for training and custom python for normalization. In general, the pipeline cleans data, organizes it into a list of lists format that works for the Word2Vec module and trains a model. I’ll explain how each of those steps is performed below.
The normalize_corpus Method
Let’s start with the normalization step which can be tricky given the fact that the dataset can sometimes present diacritics or characters not expected in English. We developed a regular expression that permits us to search and find all the valid text from the Mexican Spanish dataset.
from gensim.models import Word2Vec
import numpy as np
import re
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
plt.style.use('ggplot')
def normalize_corpus(raw_corpus):
"""
This function reads clean text. There is a read attribute for the text.
Argument: a file path that contains a well formed txt file.
Returns: This returns a 'list of lists' format friendly to Gensim. Depending on the size of the
""
raw_corpus = open(raw_corpus,'r', encoding='utf-8').read().splitlines()
#This is the simple way to remove stop words
formatted_sentences=[]
for sentences in raw_corpus:
a_words = re.findall(r'[A-Za-z\-0-9\w+á\w+\w+é\w+\w+í\w+\w+ó\w+\w+ú\w+]+', sentences.lower())
formatted_sentences.append(a_words)
return formatted_sentences
important_text = normalize_corpus(<<file-path>>)Once we generate a list of formatted sentences, which consists of lists of lists containing strings (a single list is a ‘document’), we can use that total set of lists as input for a model. Building the model is likely the easiest part, but formatting the data and compiling it in a usable manner is the hardest. For instance, the document below is an ordered, normalized and tokenized list of strings from this Mexican Spanish News corpus. Feel free to copy/paste in case you want to review the nature of this document:
['piden', 'estrategia', 'inmediata', 'para', 'capacitar', 'policías', 'recientemente', 'se', 'han', 'registrado', 'al', 'menos', 'tres', 'casos', 'de', 'abuso', 'de', 'la', 'fuerza', 'por', 'parte', 'de', 'elementos', 'policiales', 'en', 'los', 'estados', 'de', 'jalisco', 'y', 'en', 'la', 'ciudad', 'de', 'méxico', 'el', 'economista', 'organizaciones', 'sociales', 'coincidieron', 'en', 'que', 'la', 'relación', 'entre', 'ciudadanos', 'y', 'policías', 'no', 'debe', 'ser', 'de', 'adversarios', 'y', 'las', 'autoridades', 'tanto', 'a', 'nivel', 'federal', 'como', 'local', 'deben', 'plantear', 'una', 'estrategia', 'inmediata', 'y', 'un', 'proyecto', 'a', 'largo', 'plazo', 'para', 'garantizar', 'la', 'profesionalización', 'de', 'los', 'mandos', 'policiacos', 'con', 'apego', 'a', 'los', 'derechos', 'humanos', 'recientemente', 'se', 'han', 'difundido', 'tres', 'casos', 'de', 'abuso', 'policial', 'el', 'primero', 'fue', 'el', 'de', 'giovanni', 'lópez', 'quien', 'fue', 'asesinado', 'en', 'jalisco', 'posteriormente', 'la', 'agresión', 'por', 'parte', 'de', 'policías', 'capitalinos', 'contra', 'una', 'menor', 'de', 'edad', 'durante', 'una', 'manifestación', 'y', 'el', 'tercero', 'fue', 'el', 'asesinato', 'de', 'un', 'hombre', 'en', 'la', 'alcaldía', 'coyoacán', 'en', 'la', 'cdmx', 'a', 'manos', 'de', 'policías', 'entrevistada', 'por', 'el', 'economista', 'la', 'presidenta', 'de', 'causa', 'en', 'común', 'maría', 'elena', 'morera', 'destacó', 'que', 'en', 'ningún', 'caso', 'es', 'admisible', 'que', 'los', 'mandos', 'policiales', 'abusen', 'de', 'las', 'y', 'los', 'ciudadanos', 'y', 'si', 'bien', 'la', 'responsabilidad', 'recae', 'sobre', 'el', 'uniformado', 'que', 'actúa', 'las', 'instituciones', 'deben', 'garantizar', 'la', 'profesionalización', 'de', 'los', 'elementos', 'los', 'policías', 'son', 'un', 'reflejo', 'de', 'la', 'sociedad', 'a', 'la', 'que', 'sirven', 'y', 'ello', 'refleja', 'que', 'hay', 'una', 'sociedad', 'sumamente', 'violenta', 'y', 'ellos', 'también', 'lo', 'son', 'y', 'no', 'lo', 'controlan', 'declaró', 'que', 'más', 'allá', 'de', 'que', 'el', 'gobernador', 'de', 'jalisco', 'enrique', 'alfaro', 'y', 'la', 'jefa', 'de', 'gobierno', 'de', 'la', 'cdmx', 'claudia', 'sheinbaum', 'condenen', 'los', 'hechos', 'y', 'aseguren', 'que', 'no', 'se', 'tolerará', 'el', 'abuso', 'policial', 'deben', 'iniciar', 'una', 'investigación', 'tanto', 'a', 'los', 'uniformados', 'involucrados', 'como', 'a', 'las', 'fiscalías', 'sobre', 'las', 'marchas', 'agregó', 'que', 'si', 'bien', 'las', 'policías', 'no', 'pueden', 'lastimar', 'a', 'las', 'personas', 'que', 'ejercen', 'su', 'derecho', 'a', 'la', 'libre', 'expresión', 'dijo', 'que', 'hay', 'civiles', 'que', 'no', 'se', 'encuentran', 'dentro', 'de', 'los', 'movimientos', 'y', 'son', 'agredidos', 'es', 'importante', 'decir', 'quién', 'está', 'tras', 'estas', 'manifestaciones', 'violentas', 'en', 'esta', 'semana', 'vimos', 'que', 'no', 'era', 'un', 'grupo', 'de', 'mujeres', 'luchando', 'por', 'sus', 'derechos', 'sino', 'que', 'fueron', 'grupos', 'violentos', 'enviados', 'a', 'generar', 'estos', 'actos', 'entonces', 'es', 'necesario', 'definir', 'qué', 'grupos', 'políticos', 'están', 'detrás', 'de', 'esto', 'puntualizó', 'el', 'coordinador', 'del', 'programa', 'de', 'seguridad', 'de', 'méxico', 'evalúa', 'david', 'ramírez', 'de', 'garay', 'dijo', 'que', 'las', 'autoridades', 'deben', 'de', 'ocuparse', 'en', 'plantear', 'una', 'estrategia', 'a', 'largo', 'plazo', 'para', 'que', 'las', 'instituciones', 'de', 'seguridad', 'tengan', 'la', 'estructura', 'suficiente', 'para', 'llevar', 'a', 'cabo', 'sus', 'labores', 'y', 'sobre', 'todo', 'tengan', 'como', 'objetivo', 'atender', 'a', 'la', 'ciudadanía', 'para', 'generar', 'confianza', 'entre', 'ellos', 'desde', 'hace', 'muchos', 'años', 'no', 'vemos', 'que', 'la', 'sociedad', 'o', 'los', 'gobiernos', 'federales', 'y', 'locales', 'tomen', 'en', 'serio', 'el', 'tema', 'de', 'las', 'policías', 'y', 'la', 'relación', 'que', 'tienen', 'con', 'la', 'comunidad', 'lo', 'que', 'estamos', 'viviendo', 'es', 'el', 'gran', 'rezago', 'que', 'hemos', 'dejado', 'que', 'se', 'acumule', 'en', 'las', 'instituciones', 'de', 'seguridad', 'indicó', 'el', 'especialista', 'apuntó', 'que', 'además', 'de', 'la', 'falta', 'de', 'capacitación', 'las', 'instituciones', 'policiales', 'se', 'enfrentan', 'a', 'la', 'carga', 'de', 'trabajo', 'la', 'falta', 'de', 'protección', 'social', 'de', 'algunos', 'uniformados', 'la', 'inexistencia', 'de', 'una', 'carrera', 'policial', 'entre', 'otras', 'deficiencias', 'la', 'jefa', 'de', 'la', 'unidad', 'de', 'derechos', 'humanos', 'de', 'amnistía', 'internacional', 'méxico', 'edith', 'olivares', 'dijo', 'que', 'la', 'relación', 'entre', 'policías', 'y', 'ciudadanía', 'no', 'debe', 'ser', 'de', 'adversarios', 'y', 'enfatizó', 'que', 'es', 'necesario', 'que', 'las', 'personas', 'detenidas', 'sean', 'entregadas', 'a', 'las', 'autoridades', 'correspondientes', 'para', 'continuar', 'con', 'el', 'proceso', 'señaló', 'que', 'este', 'lapso', 'es', 'el', 'de', 'mayor', 'riesgo', 'para', 'las', 'personas', 'que', 'son', 'detenidas', 'al', 'tiempo', 'que', 'insistió', 'en', 'que', 'las', 'personas', 'encargadas', 'de', 'realizar', 'detenciones', 'deben', 'tener', 'geolocalización', 'no', 'observamos', 'que', 'haya', 'una', 'política', 'sostenida', 'de', 'fortalecimiento', 'de', 'los', 'cuerpos', 'policiales', 'para', 'que', 'actúen', 'con', 'apego', 'a', 'los', 'derechos', 'humanos', 'lo', 'otro', 'que', 'observamos', 'es', 'que', 'diferentes', 'cuerpos', 'policiales', 'cuando', 'actúan', 'en', 'conjunto', 'no', 'necesariamente', 'lo', 'hacen', 'de', 'manera', 'coordinada']We build the model with just a few lines of python code once the lists of lists are contained in an object. The next step is to provide these lists as the argument of the Word2Vec in the object important_text. The Word2Vec module has a few relevant commands and arguments, which I will not review in depth here.
from gensim.models import Word2Vec
important_text = normalize_corpus(<<file-path>>)
mexican_model = Word2Vec(important_text, vector_size=100, window=5, min_count=5, workers=10)
mexican_model.save("NewMod1el.w2v")The scatterplot Method: Visualizing Data
The scatter plot method for vectors allows for quick visualization of similar terms. The scatterplot function uses as an argument a model that contains all the vector representations of the Spanish MX content.
def scatter_vector(modelo, palabra, size, topn):
""" This scatter plot for vectors allows for quick visualization of similar terms.
Argument: a model containing vector representations of the Spanish MX content. word
is the content you're looking for in the corpus.
Return: close words
"""
arr = np.empty((0,size), dtype='f')
word_labels = [palabra]
palabras_cercanas = modelo.wv.similar_by_word(palabra, topn=topn)
arr = np.append(arr, np.array([modelo.wv[palabra]]), axis=0)
for wrd_score in palabras_cercanas:
wrd_vector = modelo.wv[wrd_score[0]]
word_labels.append(wrd_score[0])
arr = np.append(arr, np.array([wrd_vector]), axis=0)
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(arr)
x_coords = Y[:, 0]
y_coords = Y[:, 1]
plt.scatter(x_coords, y_coords)
for label, x, y in zip(word_labels, x_coords, y_coords):
plt.annotate(label, xy=(x, y), xytext=(0, 0), textcoords='offset points')
plt.xlim(x_coords.min()+0.00005, x_coords.max()+0.00005)
plt.ylim(y_coords.min()+0.00005, y_coords.max()+0.00005)
plt.show()
return palabras_cercanas
scatter_vector(modelo, 'coronavirus', 100, 21)Coronavirus Word Vectors
The coronavirus corpus contained here is Mexico centric in it’s discussions. Generally, it was sourced from a combination of mainstream news sources, like La Jornada, and smaller digital only press, like SemMexico.
We used ‘Word2Vec’ to develop vector graph representations of words. This will allow us to rank the level of similarity between words with a number between 0 and 1. Word2Vec is a python module for indexing the shared context of words and then representing each as a vector/graph. Each vector is supposed to stand-in as a representation of meanning proximity based on word usage. We used Word2Vec to develop a semantic similarity representation for Coronavirus terminology within news coverage.
In this set of about 1200 documents, we created a vector model for key terms in the document; the printed results below show how related the other words are related to our target word ‘coronavirus‘. The most similar term was ‘covid-19’, virus and a shortening ‘covid’. The validity of these results were obvious enough and indicate that our document set contains enough content to represent our intuitions of this topic.
[('covid-19', 0.8591713309288025),
('virus', 0.8252751231193542),
('covid', 0.7919320464134216),
('sars-cov-2', 0.7188869118690491),
('covid19', 0.6791930794715881),
('influenza', 0.6357837319374084),
('dengue', 0.6119976043701172),
('enfermedad', 0.5872418880462646),
('pico', 0.5461580753326416),
('anticuerpos', 0.5339271426200867),
('ébola', 0.5207288861274719),
('repunte', 0.520190417766571),
('pandémica', 0.5115000605583191),
('infección', 0.5103719234466553),
('fumigación', 0.5102646946907043),
('alza', 0.4952083230018616),
('detectada', 0.4907490015029907),
('sars', 0.48677393794059753),
('curva', 0.48023557662963867),
('descenso', 0.4770597517490387),
('confinamiento', 0.4769912660121918)]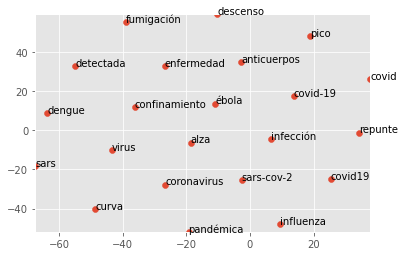
One of the measures for the merit of a large machine learning model is if the output aligns with the intuition of a human judgement. This implies that we should ask ourselves if the topmost ranked ‘similar’ words presented by this word2vec model matches up with our psychological opinion of ‘coronavirus’. Overwhelmingly, the answer is ‘yes’, since Covid and Covid19 nearly always mean the same thing, without a hyphen or if referenced as just ‘virus’ in some texts’.
Strong Normalization Leads To Better Vectors
Better normalization leads to better vectors.
This is verifiable in a scatterplot comparing the distinct text normalization that one intuits is best upon analyzing initial training data.
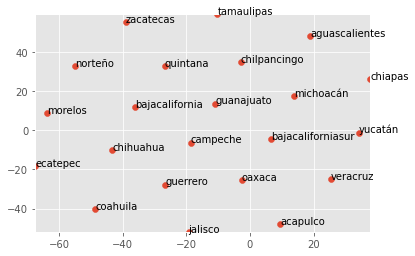
For example, many place names are effectively compound words or complex strings which can lead to misleading segmentation. This adds noise, effectively misaligning other words in the word vector model. Therefore, finding a quick way to ensure place names are represented accurately helps other unrelated terms surface away from their vector representation. Consider this below scatterplot where the names ‘baja california sur’ and ‘baja california’ are not properly tokenized:
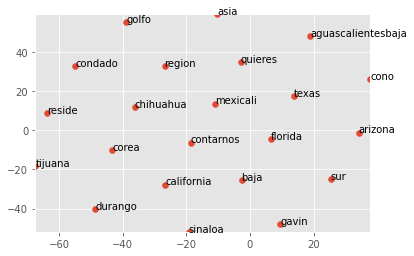
Replacing the spaces between ‘Baja California Sur’, ‘Baja California’, and ‘Sur de California’, allows for other place names that pattern similarly to shine through in the scatterplot. This reflects more accurate word vector representations.