Frequency Counts For Named Entities Using Spacy/Python Over MX Spanish News Text
On this post, we review some straightforward code written in python that allows a user to process text and retrieve named entities alongside their numerical counts. The main dependencies are Spacy, a small compact version of their Spanish language model built for Named Entity Recognition and the tabular data processing library, Matplotlib, if you’re looking to further structure the data.
Motivation(s)
Before we begin, it may be relevant to understand why we would want to extract these data points in the first place. Often times, there is a benefit to quickly knowing what named entity a collection (or even a hadoop sized bucket) of stories references. For instance, one of the benefits is the quick ability to visualize the relative importance of an entity to these stories without having to read all of them.
Even if done automatically, the process of Named Entity Recognition is still guided by very basic principles, I think. For instance, the very basic reasoning surrounding a retelling of events for an elementary school summary applies to the domain of Named Entity Recognition. That is mentioned below in the Wh-question section of this post.
Where did you get this data?
Another important set of questions is what data are we analyzing and how did we gather this dataset?
Ultimately, a great number of computational linguists or NLP practitioners are interested in compiling human rights centered corpora to create tools that analyze newsflow quickly on these points. When dealing with sensitive topics, the data has to center on those related topics for at-need populations. This specific dataset centers around ‘Women/Women’s Issues’ as specified by the group at SugarBearAI.
As for ‘where did they obtain this data‘?, that question is answered as follows: this dataset of six hundred articles existing in the LaCartita Db – which contains several thousand hand-tagged articles – is annotated by hand. The annotators are a group of Mexican graduates from UNAM and IPN universities. A uniform consensus amongst the news taggers was required for its introduction into the set of documents. There were 3 women and 1 man within the group of analysts, with all of them having prior experience gathering data in this domain.
While the six hundred Mexican Spanish news headlines analyzed are unavailable on github, a smaller set is provided on that platform for educational purposes. Under all conditions, the data was tokenized and normalized with a fairly sophisticated set of Spanish centric regular expressions.
Please feel free to reach out to that group in research@lacartita.com for more information on this hand-tagged dataset.
Wh-Questions That Guide News Judgments
With all of the context on data and motivations in mind, we review some points on news judgment that can help with the selection of texts for analysis and guide the interpretation of automatically extracted data points.
Basic news judgment is often informed by the following Wh-questions:
1.) What occurred in this news event? (Topic Classification; Event Extraction)
2.) Who was involved in the news?
3.) When did this news event take place?
4.) Where did it take place?
5.) Why did this take place?
If you think of these questions at a fairly high level of abstraction, then you’ll allow me to posit that the first two questions are often the domain of Topic Classification and Named Entity Recognition, respectively. This post will deal with the latter, but assume that this issue of extracting named entities deals with documents already organized on the basis of some unifying topic. This is why it’s useful to even engage in the activity.
In other words, you – the user of this library – will be open to providing a collection of documents already organized under some concept/topic. You would be relying on your knowledge of that topic to make sense of any frequency analysis of named entities, important terms (TF-IDF) etc. as is typical when handling large amounts of unstructured news text. These concepts – NER and TFIDF – are commonly referenced in Computational Linguistics and Information Retrieval; they overlap in applied settings frequently. For instance, TF-IDF and NER pipelines power software applications that deal in summarizing complex news events in real time. So, it’s important to know that there are all sorts of open source libraries that handle these tasks for any average user or researcher.
Leveraging Spacy’s Lightweight Spanish Language Model
The actual hard work involves identifying distinct entities; the task of identifying Named Entities involves statistical processes that try to generalize what a typical Named Entity’s morphological shape in text involves.
In this example, my particular script is powered by the smaller language model from Spacy. One thing that should be noted is that the text has its origins in Wikipedia. This means that newer contemporary types of text may not be sufficiently well covered – breadth doesn’t imply depth in analysis. Anecdotally, over this fairly small headline-only corpus sourced by hand with UNAM and IPN students that contains text on the Mexican president, Andres Manuel Lopez Obrador, Covid and local crime stories, we see performance below 80 percent accuracy from the small Spanish language model. Here’s the small 600 headline strong sample: example headlines referenced.
NER_News Module
Using the below scripts, you can extract persons and organizations. Using spacy, you can extract the entities extracted from a corpus. We will use the lighter Spanish language model from Spacy’s natural language toolkit. This post assumes that you’ve dealt with the basics of Spacy installation alongside its required models. If not, visit here. Therefore, we should expect the below lines to run without problem:
import spacy
import spacy.attrs
nlp = spacy.load('es_core_news_sm')In this example, we use clean texts that are ‘\n’ (“new line separated”) separated texts. We count and identify the entities writing to either memory or printing to console the results of the NER process. The following line contains the first bit of code referencing Spacy and individuates each relevant piece of the text. Suppose these were encyclopedic or news articles, then the split would probably capture paragraph or sentence level breaks in the text:
raw_corpus = open('corpora/titularesdemx.txt','r', encoding='utf-8').read().split("\n")[1:]The next step involves placing NER text with its frequency count as a value in a dictionary. This dictionary will be result of running our ‘sacalasentidades’ method over the raw corpus. The method extracts GEO-political entities, like a country, or PER-tagged entities, like a world leader.
import spacy
import spacy.attrs
nlp = spacy.load('es_core_news_sm')
import org_per
raw_corpus = open('corpora/titularesdemx.txt','r', encoding='utf-8').read().split("\n")[1:]
entities = org_per.sacalasentidades(raw_corpus)
# use list of entities that are ORG or GEO and count up each invidividual token.
tokensdictionary = org_per.map_entities(entities) The object tokensdictionary formatted output will look like this:
{'AMLO': 11,
'Desempleo': 1,
'Perú': 1,
'América Latina': 3,
'Banessa Gómez': 1,
'Resistir': 2,
'Hacienda': 1,
'Denuncian': 7,
'Madero': 1,
'Subastarán': 1,
'Sánchez Cordero': 4,
'Codhem': 1,
'Temen': 2,
'Redes de Derechos Humanos': 1,
'Gobernación': 1,
'Sufren': 1,
'¡Ni': 1,
'Exigen': 2,
'Defensoras': 1,
'Medicina': 1,
'Género': 1,
'Gabriela Rodríguez': 1,
'Beatriz Gasca Acevedo': 1,
'Diego "N': 1,
'Jessica González': 1,
'Sheinbaum': 3,
'Esfuerzo': 1,
'Incendian Cecyt': 1,
'Secretaria de Morelos': 1,
'Astudillo': 1,
'Llaman': 3,
'Refuerzan': 1,
'Mujer Rural': 1,
'Inician': 1,
'Violaciones': 1,
'Llama Olga Sánchez Cordero': 1,
'Fuentes': 1,
'Refuerza Michoacán': 1,
'Marchan': 4,
'Ayelin Gutiérrez': 1,
'Maternidades': 1,
'Coloca FIRA': 1,
'Coloquio Internacional': 1,
'Ley Olimpia': 3,
'Toallas': 1,
'Exhorta Unicef': 1,
'Condena CNDH': 1,
'Policías de Cancún': 1,
'Exposición': 1,
'Nadia López': 1,
'Aprueba la Cámara': 1,
'Patriarcales': 1,
'Sofía': 1,
'Crean Defensoría Pública para Mujeres': 1,
'Friedrich Katz': 1,
'Historiadora': 1,
'Soledad Jarquín Edgar': 1,
'Insuficientes': 1,
'Wikiclaves Violetas': 1,
'Líder': 1,
'Alcaldía Miguel Hidalgo': 1,
'Ventana de Primer Contacto': 1,
'Parteras': 1,
'App': 1,
'Consorcio Oaxaca': 2,
'Comité': 1,
'Verónica García de León': 1,
'Discapacidad': 1,
'Cuánto': 1,
'Conasami': 1,
'Amnistía': 1,
'Policía de Género': 1,
'Parteras de Chiapas': 1,
'Obligan': 1,
'Suspenden': 1,
'Contexto': 1,
'Clemencia Herrera': 1,
'Fortalecerán': 1,
'Reabrirá Fiscalía de Chihuahua': 1,
'Corral': 1,
'Refugio': 1,
'Alicia De los Ríos': 1,
'Evangelina Corona Cadena': 1,
'Félix Salgado Macedonio': 5,
'Gabriela Coutiño': 1,
'Aída Mulato': 1,
'Leydy Pech': 1,
'Claman': 1,
'Insiste Morena': 1,
'Mariana': 2,
'Marilyn Manson': 2,
'Deberá Inmujeres': 1,
'Marcos Zapotitla Becerro': 1,
'Vázquez Mota': 1,
'Dona Airbnb': 1,
'Sergio Quezada Mendoza': 1,
'Incluyan': 1,
'Feminicidios': 1,
'Contundente': 1,
'Teófila': 1,
'Félix Salgado': 1,
'Policía de Xoxocotlán': 1,
'Malú Micher': 1,
'Andrés Roemer': 1,
'Basilia Castañeda': 1,
'Salgado Macedonio': 1,
'Menstruación Digna': 1,
'Detenidas': 1,
'Sor Juana Inés de la Cruz': 1,
'María Marcela Lagarde': 1,
'Crean': 1,
'Será Rita Plancarte': 1,
'Valparaiso': 1,
'México': 1,
'Plataformas': 1,
'Policías': 1,
'Karen': 1,
'Karla': 1,
'Condena ONU Mujeres': 1,
'Llaman México': 1,
'Sara Lovera': 1,
'Artemisa Montes': 1,
'Victoria': 2,
'Andrea': 1,
'Irene Hernández': 1,
'Amnistía Internacional': 1,
'Ley de Amnistía': 1,
'Nació Suriana': 1,
'Rechaza Ss': 1,
'Refugios': 1,
'Niñas': 1,
'Fiscalía': 1,
'Alejandra Mora Mora': 1,
'Claudia Uruchurtu': 1,
'Encubren': 1,
'Continúa': 1,
'Dulce María Sauri Riancho': 1,
'Aprueba Observatorio de Participación Política de la Mujer': 1,
'Plantean': 1,
'Graciela Casas': 1,
'Carlos Morán': 1,
'Secretaría de Comunicaciones': 1,
'Diego Helguera': 1,
'Hidalgo': 1,
'LGBT+': 1,
'Osorio Chong': 1,
'Carla Humphrey Jordán': 1,
'Lorenzo Córdova': 1,
'Edomex': 1,
'CEPAL': 1,
'Delitos': 1,
'Murat': 1,
'Avanza México': 1,
'Miguel Ángel Mancera Espinosa': 1,
'Reconoce INMUJERES': 1,
'Excluyen': 1,
'Alejandro Murat': 1,
'Gómez Cazarín': 1,
'Prevenir': 1,
'Softbol MX': 1,
'Martha Sánchez Néstor': 1}Erros in Spacy Model
One of the interesting errors in the SPACY powered NER process is the erroneous tagging of ‘ Plantean’ as a named entity when, in fact, this string is a verb. Similarly, ‘Delitos’ and ‘Excluyen’ are tagged as ORG or PER tags. Possibly, the morphological shape, orthographic tendency of headlines throws off the small language model. Thus, even with this small test sample, we can see the limits of out-of-the-box open source solutions for NLP tasks. This shows the value added of language analysts, data scientists in organizations dealing with even more specific or specialized texts.
Handling Large Number of Entries On Matplotlib
One issue is that there will be more Named Entities recognized than is useful or even possible to graph.
Despite the fact that we have a valuable dictionary above, we still need to go further and trim down the dictionary in order to figure out what is truly important. In this case, the next Python snippet is helpful in cutting out all dictionary values that contain a frequency count of only ‘1’. There are occasions in which a minimum value must be set.
For instance, suppose you have 1000 documents with 1000 headlines. Your NER analyzer must read through these headlines which ultimately are not a lot of text. Therefore, the minimum count you would like to eliminate is likely to be ‘1’ while if you were analyzing the entirety of the document body, then you may want to raise the minimum threshold for a dictionary value’s frequency.
The following dictionary comprehension places a for-loop type structure that filters out on the basis of the term frequency being anything but ‘1’, the most common frequency. This is appropriate for headlines.
filter_ones = {term:frequency for term, frequency in data.items() if frequency > 1}While this dictionary filtering process is better for headlines, a higher filter is needed for body text. 10,000 words or more potentially words implies that the threshold for the minimum frequency value is higher than 10.
filter_ones = {term:frequency for term, frequency in data.items() if frequency > 10}The resulting dictionary now presented as a matplotlib figure is shown:
def plot_terms_body(topic, data):
"""
The no.aranage attribution is to understand how to best and programmatically
plot the data. Intervals are determined by the counts within the dictionary.
Args: Topic is the name of the plot/category. The 'data' is a list of ter
"""
#The bar plot should be optimized for the max and min size of
#individual
filter_ones = {term:frequency for term, frequency in data.items() if frequency > 10}
filtered = {term:frequency for term, frequency in data.items() if frequency > round(sum(filter_ones.values())/len(filter_ones)) }
print(round(sum(filtered.values())/len(filtered)), "Average count as result of total terms minus once identified terms divided by all terms.")
terms = filtered.keys()
frequency = filtered.values()
y_pos = np.arange(len(terms),step=1)
# min dictionary value, max filtered value ;
x_pos = np.arange(min(filtered.values()), max(filtered.values()), step=round(sum(filtered.values())/len(filtered)))
plt.barh(y_pos, frequency, align='center', alpha=1)
plt.yticks(y_pos, terms, fontsize=12)
plt.xticks(x_pos)
plt.xlabel('Frecuencia en encabezados')
plt.title(str(topic), fontsize=14)
plt.tight_layout()
plt.show()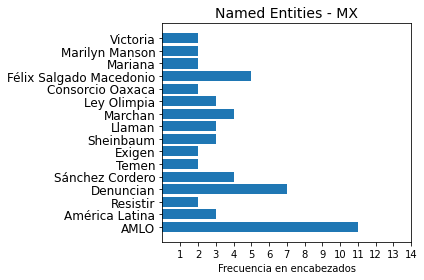
We are able to extract the most common GER or PER tagged Named Entities in a ‘Women’ tagged set of documents sourced from Mexican Spanish news text.
Surprise, surprise, the terms ‘Exigen‘, ‘Llaman‘, ‘Marchan‘ cause problems due to their morphological and textual shape; the term ‘Victoria‘ is orthographically identical and homophonous to a proper names, but in this case, it is not a Named Entities. These false positives in the NER process from Spacy just reflects how language models should be trained over specific texts for better performance. Perhaps, an NER model trained over headlines would fare better. The data was already cleaned due to a collection process detailed below so normalization and tokenization were handled beforehand.