N-Gram Analysis Over Sensitive Topics Corpus
I was recently able to do some analysis over the Sugar Bear AI violence corpus, a collection of documents classified by analysts over at the SugarBear AI group. The group has been classifying manually thousands of documents of Mexican Spanish news over the past year that deal with the new topics of today: “Coronavirus”, “WFH”, as well as pressing social issues that have only recently come to the fore of mainstream news. Since the start of the pandemic, they’ve made some of their material available online, but the content is mostly for sale as the Mexico City based group needs to eat. That aside, they produce super-clean and super-specific ‘Sensitive Topics‘ data.
There is a growing consensus that solid data and analysis is needed for NLP activities that involve specific topics, like human rights or documents referencing cultural minorities in any region. For instance, we can not reasonably expect webscraped data from Reddit to fulfill the NLP needs of the Mexican Spanish speaking communities residing outside of official borders. As a whole, the worldview of Reddit as encoded in its texts will not reflect adequately on the needs or key ideas held within that population. Basic NLP tasks, then, like mining for best autocompleted answers, searches or key terms can not be sourced from such a demographic specific (White, 18-45, Male) corpus.
Stopwords
We will work over a couple of hundred documents and try to see what inferences can be drawn from this short sample. We definitely need a new stopword lists. This can help filter out ‘noise’ that is specific to the domain we’re researching. The list(s) can be expanded over time – NLTK’s default Spanish is not enough – and, while there may be some incentive to work with an existing list, the bigrams below show why we would need a domain specific list, one in Spanish and developed by analysts who looked at this data continually.
N-Gram Analysis
As alluded to above, we will start with an N-gram analysis.
To put it simply, N-Grams are units of strings in text that appear with some amount of frequency over a given text. The strings are called ‘tokens’; what specific guidelines on how strings are defined as a token depends on the developers of a corpus. They may have specific applications in mind when developing a corpus. In the case of the Sugar Bear AI, the most relevant application is the development of a news classifier for sensitive topics in Mexico.
We used NLTK to sample out what a basic N-Gram analysis would yield. As is typical in news text, this corpus contained dates, non-alphanumeric content, but no emojis or content associated with social media. The actual analysis from the NTLK ngram module is sufficient for our purposes. That being said, some modest use of the tokenized module and regular expressions did the trick of ‘normalizing’ the text. Linguists should leverage basic notions of Regular Expressions.
if not re.match("[^a-zA-Z]", i) and not re.match("[^a-zA-Z]", j) The violence corpus is fairly small but it is not static. The Mexico City based Sugar Bear Ai group continues to annotate at the document level content from alternative and Mexican mainstream news sources. In the set referenced here, there are about 400 documents from 8 different news sources in Mexico. The careful approach to its curation and collection, however, ensures any researcher working with the corpus will have a balanced and not commonly analyzed collection of texts on sensitive topics.
Code Description
The code here presents a manner in which a list (any list) can be processed by NLTK’s ngram module, but also normalized with some basic tokenization and stop
import re
from nltk.corpus import stopwords
def find_bigrams(t):
list = []
for a in t:
token = nltk.word_tokenize(a)
stop_words = set(stopwords.words('spanish'))
filtered_sentence = [w for w in token if not w in stop_words]
bigrams = ngrams(filtered_sentence,2)
for i, j in bigrams:
if not re.match("[^a-zA-Z]", i) and not re.match("[^a-zA-Z]", j) :
list.append("{0} {1}".format(i, j))
return list
alpha = find_bigrams(list)
...| frente múltiples |
| visité cerca |
| absoluto atrocidades |
| consejeras rendirán |
| ser derechos |
| Vazquez hijo |
| detenga amenazas |
| puntos pliego |
| odisea huyen |
| anunció separación |
| Covid-19 debe |
| víctima frente |
| Acapulco sentenciar |
| logró enviar |
| garantías acceso |
| documentaron atención |
| Atendiendo publicación |
| llamado Estados |
| interior Estaciones |
| encuentran mayoría |
| informativas pandemia |
| relación familiar |
| comunidad Agua |
| día finalizar |
| Jornada Ecatepec |
| lenta momento |
| guerras territoriales |
| Pese Facebook |
| pedido retiro |
| Rendón cuenta |
| A.C. Mujeres |
| error quizá |
| iniciativas enfocadas |
| consciente anticapitalista |
| afectar mujer |
| Justicia u |
| alertas tempranas |
| mediante expresión |
| Nahuatzen comunidad |
| garantizar repetición |
| alza indicadores |
| noche martes |
| creó Guardia |
| asegura feminicidio |
| Unión Fuerza |
| pronunciamiento Red |
| carbono equivalente |
| condiciones desarrollo |
| comparativo agresiones |
| recorte refugios |
| agregó pesar |
The Ngrams represent a small sampling of typical speech within the ‘violence’ corpus. The usual steps to normalize the content were taken, but, as already mentioned, domain specific stop-word list should be developed.
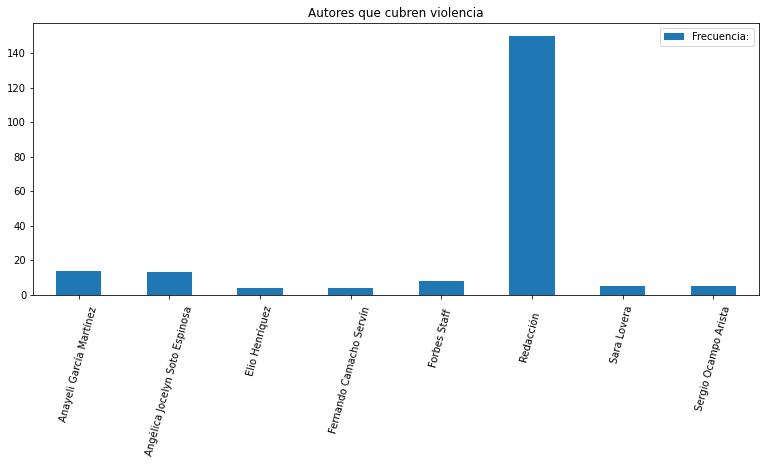
Interesting Patterns In Authorship, Anonymity
Another interesting insight about this small dataset is that the document set or topic has a usual set of authors. Either its a few authors from a small blog or a large institution(s) publishing without attribution. You can read the Spanish texts here. I share the graph about how attribution and which media groups cover the topic of ‘Violence’ in Mexico.
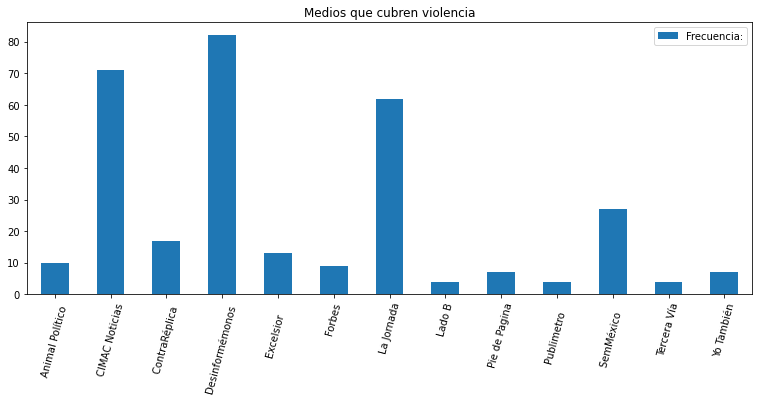
Most large institutions, like El Financiero or even La Jornada, are capable of finding insight on impactful events, like a major violation of human rights, but they do so anonymously. Larger institutions are better able to publish content without attribution, which translates into potentially less risk for their staff.